Overview
Goal: Predict product classification by customer complaints
Key word: TF-IDF, Multinomial Naive Bayes, Logistic Regression, Linear SVC
Data Source: https://data.consumerfinance.gov/dataset/Consumer-Complaints/s6ew-h6mp
# import necessary packages
import pandas as pd
import numpy as np
import seaborn as sns
from collections import Counter
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split as split
from sklearn.feature_extraction import text
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
from sklearn.metrics import confusion_matrix
I. Data Clean
# read in csv file as pandas dataframe
df1 = pd.read_csv('Consumer_Complaints.csv')
df = df1.copy()
df.shape
(1128890, 18)
# Handle missing values / NaN values.
missing_count = df.isnull().sum()
missing_count
Date received 0
Product 0
Sub-product 235168
Issue 0
Sub-issue 510840
Consumer complaint narrative 803619
Company public response 757475
Company 0
State 14508
ZIP code 86398
Tags 973971
Consumer consent provided? 552221
Submitted via 0
Date sent to company 0
Company response to consumer 6
Timely response? 0
Consumer disputed? 360354
Complaint ID 0
dtype: int64
# discard the rows where consumer complaint narrative is blank
df = df[df['Consumer complaint narrative'].notnull()]
df.shape
(325271, 18)
# current missing values
missing_count = df.isnull().sum()
missing_count
Date received 0
Product 0
Sub-product 52173
Issue 0
Sub-issue 105691
Consumer complaint narrative 0
Company public response 168075
Company 0
State 1208
ZIP code 68620
Tags 269162
Consumer consent provided? 0
Submitted via 0
Date sent to company 0
Company response to consumer 4
Timely response? 0
Consumer disputed? 161180
Complaint ID 0
dtype: int64
II. Data Exploration
plt.hist(df.groupby('Company')['Consumer complaint narrative'].count().sort_values(ascending=False).head(20))
(array([10., 1., 2., 4., 0., 0., 0., 2., 0., 1.]),
array([ 2204. , 5124.2, 8044.4, 10964.6, 13884.8, 16805. , 19725.2,
22645.4, 25565.6, 28485.8, 31406. ]),
<a list of 10 Patch objects>)
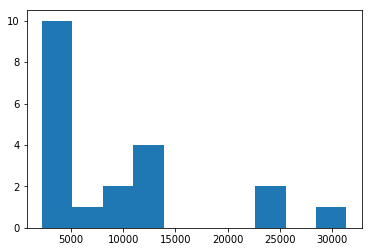
df.groupby('Company')['Consumer complaint narrative'].count().sort_values(ascending=False).head(20).plot.bar(ylim=0)
plt.show()
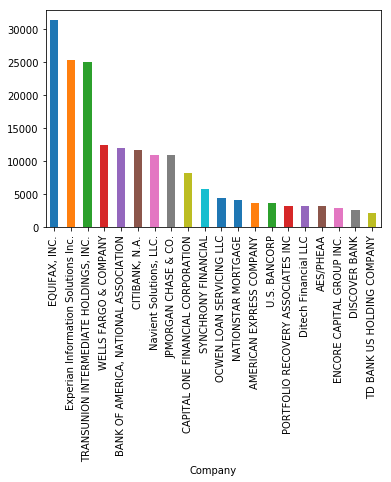
df.groupby('Company')['Consumer complaint narrative'].count().sort_values(ascending=False).head(20)
Company
EQUIFAX, INC. 31406
Experian Information Solutions Inc. 25433
TRANSUNION INTERMEDIATE HOLDINGS, INC. 25103
WELLS FARGO & COMPANY 12422
BANK OF AMERICA, NATIONAL ASSOCIATION 11967
CITIBANK, N.A. 11738
Navient Solutions, LLC. 10971
JPMORGAN CHASE & CO. 10945
CAPITAL ONE FINANCIAL CORPORATION 8280
SYNCHRONY FINANCIAL 5874
OCWEN LOAN SERVICING LLC 4471
NATIONSTAR MORTGAGE 4150
AMERICAN EXPRESS COMPANY 3718
U.S. BANCORP 3713
PORTFOLIO RECOVERY ASSOCIATES INC 3267
Ditech Financial LLC 3257
AES/PHEAA 3238
ENCORE CAPITAL GROUP INC. 2957
DISCOVER BANK 2578
TD BANK US HOLDING COMPANY 2204
Name: Consumer complaint narrative, dtype: int64
# keep product and consumer complaint narrative only
col = ['Product', 'Consumer complaint narrative']
pro_ccn = df[col]
pro_ccn.columns = ['Product', 'Consumer_complaint_narrative']
pro_ccn.head()
| Product | Consumer_complaint_narrative | |
|---|---|---|
| 1 | Student loan | When my loan was switched over to Navient i wa... |
| 2 | Credit card or prepaid card | I tried to sign up for a spending monitoring p... |
| 7 | Mortgage | My mortgage is with BB & T Bank, recently I ha... |
| 13 | Mortgage | The entire lending experience with Citizens Ba... |
| 14 | Credit reporting | My credit score has gone down XXXX points in t... |
# retreive product id as a new column
product_id = pd.factorize(pro_ccn['Product'])[0]
pro_ccn = pro_ccn.copy()
pro_ccn.loc[:,'product_id'] = product_id
pro_ccn.head()
| Product | Consumer_complaint_narrative | product_id | |
|---|---|---|---|
| 1 | Student loan | When my loan was switched over to Navient i wa... | 0 |
| 2 | Credit card or prepaid card | I tried to sign up for a spending monitoring p... | 1 |
| 7 | Mortgage | My mortgage is with BB & T Bank, recently I ha... | 2 |
| 13 | Mortgage | The entire lending experience with Citizens Ba... | 2 |
| 14 | Credit reporting | My credit score has gone down XXXX points in t... | 3 |
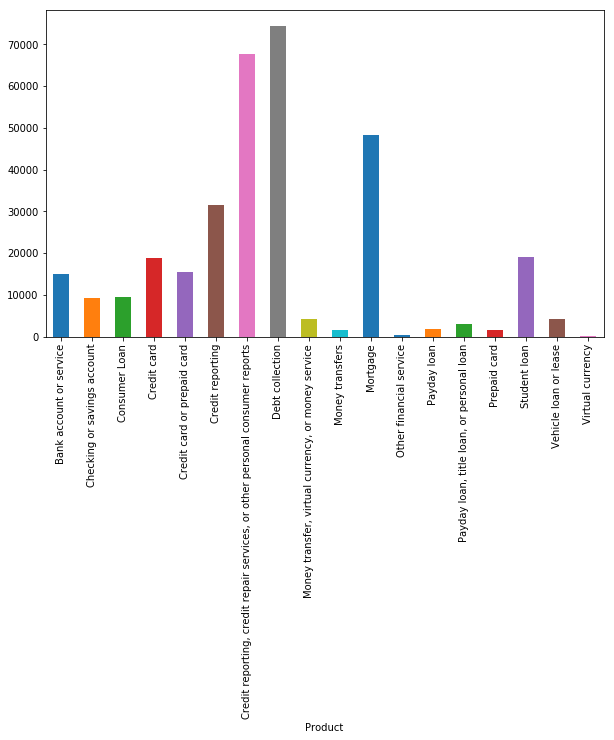
# show product distribution
plt.figure(figsize=(10,6))
pro_ccn.groupby('Product').Consumer_complaint_narrative.count().plot.bar(ylim=0)
plt.show()
# Imbalanced classes
III. Model Selection
Since it is a classification problem basically, I will consider of some classification models, such as Linear SVM, Logistic Regression and Naive Bayes.
# split data to train, validation, test
# due to large amount of data, split validation manually
train, validate, test = np.split(pro_ccn.sample(frac=1), [int(.6*len(pro_ccn)), int(.8*len(pro_ccn))])
# customerize stop words
cust_stop_words = text.ENGLISH_STOP_WORDS.union(["xxxx"])
# train the model by Naive Bayes
clf_NB = Pipeline([('vect', CountVectorizer(min_df=5, encoding='utf-8', ngram_range=(1,2), stop_words=cust_stop_words)),
('tfidf', TfidfTransformer()),
('clf', MultinomialNB()),
])
clf_NB.fit(train.Consumer_complaint_narrative, train.Product)
Pipeline(memory=None,
steps=[('vect', CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=5,
ngram_range=(1, 2), preprocessor=None,
stop_words=frozenset({...inear_tf=False, use_idf=True)), ('clf', MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True))])
# score by Naive Bayes on validation
predicted_NB = clf_NB.predict(validate.Consumer_complaint_narrative)
score_validate_NB=np.mean(predicted_NB == validate.Product)
print("The score by Naive Bayes based on validation data is {}".format(score_validate_NB))
The score by Naive Bayes based on validation data is 0.6002398007808897
# train model by logistic regression
logreg = Pipeline([('vect', CountVectorizer(min_df=5, encoding='utf-8', ngram_range=(1,2), stop_words=cust_stop_words)),
('tfidf', TfidfTransformer()),
('clf', LogisticRegression(solver='sag',multi_class ='auto')),])
logreg.fit(train.Consumer_complaint_narrative, train.Product)
Pipeline(memory=None,
steps=[('vect', CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=5,
ngram_range=(1, 2), preprocessor=None,
stop_words=frozenset({... penalty='l2', random_state=None, solver='sag',
tol=0.0001, verbose=0, warm_start=False))])
# score by logistic regression
predicted_logreg = logreg.predict(validate.Consumer_complaint_narrative)
score_validate_logreg=np.mean(predicted_logreg == validate.Product)
print("The score by logistic regression based on validation data is {}".format(score_validate_logreg))
The score by logistic regression based on validation data is 0.7493620684354536
# train model by Linear SVM
model_svm = Pipeline([('vect', CountVectorizer(min_df=5, encoding='utf-8', ngram_range=(1,2), stop_words=cust_stop_words)),
('tfidf', TfidfTransformer()),
('clf', LinearSVC(),)])
model_svm.fit(train.Consumer_complaint_narrative, train.Product)
Pipeline(memory=None,
steps=[('vect', CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=5,
ngram_range=(1, 2), preprocessor=None,
stop_words=frozenset({...ax_iter=1000,
multi_class='ovr', penalty='l2', random_state=None, tol=0.0001,
verbose=0))])
# score by LinearSVM
predicted_LSVM = model_svm.predict(validate.Consumer_complaint_narrative)
score_validate_LSVM=np.mean(predicted_LSVM == validate.Product)
print("The score by SVM based on validation data is {}".format(score_validate_LSVM))
The score by SVM based on validation data is 0.7651028376425738
IV. Model Evaluation
# The highest score of validation data is from SVM model.
# test the SVM model by test data
test_predicted_SVM = model_svm.predict(test.Consumer_complaint_narrative)
score_test_SVM=np.mean(test_predicted_SVM == test.Product)
print("The accuracy by SVM based on test data is {}".format(score_test_SVM))
The accuracy by SVM based on test data is 0.7622780724002767
# classification report
from sklearn.metrics import classification_report
# target_names = test.Product.values
print(classification_report(test.Product, test_predicted_SVM))
precision recall f1-score support
Bank account or service 0.63 0.67 0.65 2990
Checking or savings account 0.61 0.48 0.53 1872
Consumer Loan 0.55 0.46 0.50 1917
Credit card 0.61 0.62 0.61 3775
Credit card or prepaid card 0.58 0.51 0.54 3076
Credit reporting 0.72 0.62 0.66 6240
Credit reporting, credit repair services, or other personal consumer reports 0.76 0.82 0.79 13532
Debt collection 0.81 0.88 0.84 14992
Money transfer, virtual currency, or money service 0.71 0.66 0.68 810
Money transfers 0.56 0.33 0.41 309
Mortgage 0.90 0.96 0.93 9580
Other financial service 0.25 0.04 0.06 57
Payday loan 0.50 0.27 0.35 364
Payday loan, title loan, or personal loan 0.53 0.25 0.34 661
Prepaid card 0.66 0.55 0.60 288
Student loan 0.88 0.88 0.88 3760
Vehicle loan or lease 0.54 0.24 0.33 830
Virtual currency 1.00 0.50 0.67 2
micro avg 0.76 0.76 0.76 65055
macro avg 0.65 0.54 0.58 65055
weighted avg 0.75 0.76 0.75 65055
The product ‘Mortage’ has the hightest precision and recall. It may resulted from its large amount and no silimar words in complaints as other products. And the product ‘Other financial service’ has the leaset precision and recall, since its amount is small and it may have some similar word in complaints like other financal products.
In addition, the recall is usually lower than precision in less amount of products.
product_list = test.Product.values
# confusion matrix
conf_matrix = confusion_matrix(test.Product, test_predicted_SVM)
fig, ax = plt.subplots(figsize=(20,10))
sns.heatmap(conf_matrix, annot=True)
plt.ylabel('Actual Product')
plt.xlabel('Predicted Product')
plt.show()
# xticklabels=product_list, yticklabels=product_list
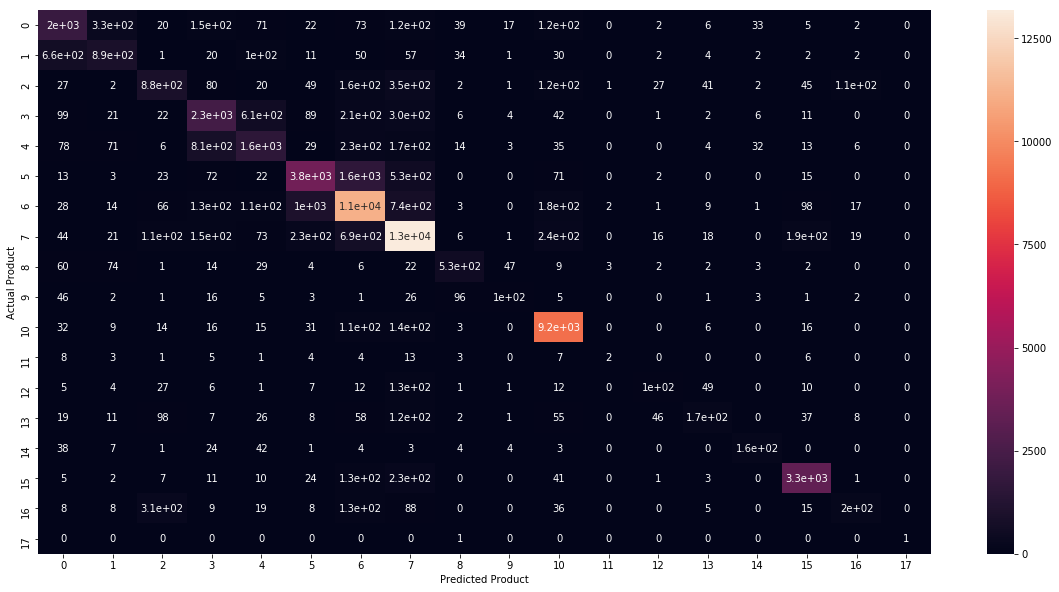
Basically, the color of the confusion matrix is not so clear since the classes are imbalanced. But, it is still more detailed than classification report.
It also shows that the prediction of 10th product, ‘Mortage’ has the highest accuracy. And 3th -7th products, related with credit, are always predicted as each others. It may be caused by similar classification of these products. That is, ‘Credit card’ product and ‘Credit card or prepaid card’ are intrinsically related. Thus it is hard to avoid this kind of misclassifications.
Overall, the model is not bad but can be improved by more process in imbalance classes and tuning parameters.